

Data panel adalah suatu tipe data longitudinal atau data yang dikumpulkan dari poin-poin berbeda dalam waktu.
Tiga tipe dari data longitudinal:
Data Time series
Banyak observasi (t kecil) dari sedikitnya satu unit (N kecil). Contoh: tren harga saham, statistik nasional agregat.
Data Pooled Cross Sections
Dua atau lebih sampel independen dari banyak unit-unit (N besar) diambil dari populasi yang sama dalam periode waktu yang berbeda. Contoh: Survai Sosial Umum, Survai Penduduk.
Data Panel
Dua atau lebih observasi (t kecil) dari banyak unit (N besar). Contoh: Survai panel pada rumah tangga dan individu, data organisasi dan firma di poin waktu yang berbeda.
Penjelasan ini merupakan pengenalan dasar untuk analisis data panel. Pada intinya akan dibahas model linier komponen error.
Mengapa data panel dianalisis?
Kita tertarik untuk mendeskrisikan perubahan antar periode waktu
- Perubahan sosial contohnya perubahan perilaku, perubahan hubungan sosial
- Pertumbuhan individu contohnya pertumbuhan anak, prestasi sekolah
- Kerjadian atau ketidakjadian suatu hal
Kita menginginkan tren superior estimate dari fenomena sosial
- Data panel dapat digunakan untuk menginformasikan kebijakan contohnya kesehatan, obesitas
- Obesrvasi yang multipel dari suatu unit bisa menyediakan estimasi yang lebih baik dibandingkan dengan model asosiasi cross sections
Kita menginginkan untuk mengestimasi model kausal
- Evaluasi kebijakan
- Estimasi dari efek perlakuan
Data seperti apa yang dibutuhkan untuk analisis panel?
Dasar dari metode panel paling tidak membutuhkan dua “gelombang” pengukuran. Seperti mempertimbangkan antara IPK mahasiswa dan jam kerja selama dua semester.
Salah satu cara untuk mengorganisir data panel adalah membuat salinan dari setiap kombinasi unit dan periode waktu:
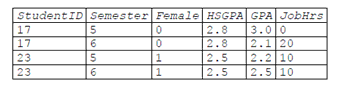
Perhatikan bahwa data meliputi:
- Identifier yang unik (StudentID)
- Hasil yang bervariasi dalam waktu (GPA)
- Indikator waktu (Semester)
Atau menggunakan format melebar:

Teknik estimasi dari data panel
Persamaan
![]()
General Linier Model (GLM) adalah dasar dari model estimasi linier panel
- Ordinary Least Square (OLS)
- Weighted Least Square (WLS)
- Generalized Least Square (GLS)
Estimasi Least Square dari model panel biasanya meliputi 3 tahapan:
- Transformasi data atau first stage estimation
- Estimasi parameter menggunakan OLS
- Estimasi matriks varian covarian (VCE)
Estimasi parameter biasanya diperhalus menggunakan iterasi terboboti least square (IRLS), suatu maksimum likelihood estimator.
Review dari Model Regresi Linier Klasik
![]()
Asumsikan bahwa model linier sesuai dan kovariat merupakan eksogenus
- Error tidak berkorelasi
- Error homoskedastisitas
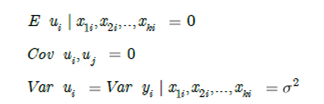
Jika asumsi tidak terpenuhi, OLS bias dan atau tidak efisien
Bias yaitu nilai harapan dari estimasi parameter berbeda dengan sebenarnya.
Konsistensi, jika estimator tidak bias, atau jika bias menciut seiring dengan membesarnya ukuran sampel, kita sebut itu KONSISTEN.
Tidak efisien yaitu estimasi kurang akurat seiring dengan meningkatnya ukuran sampel
OLS bias disebabkan karena Endogenitas
Penghilangan variabel bias : seleksi, variabel intervening dipertimbangkan ada atau tidaknya
Pengukuran error pada kovariat
Bias Simultan : feedback loops, penghilangan variabel
Strategi konvensional berbasis regresi untuk mengatasi bias endogenitas:
- Instrumental Variables estimation
- Structural Equations Models
- Propensity score estimation
- Fixed effects panel models
Ketidakefisienan OLS karena Error Berkorelasi
- Banyak struktur data yang rentan terhadap korelasi residual
- Sampel data hirarki. Contoh: anggota rumah tangga, pekerja di perusahaan
- Sampel probabilitas bertingkat sering menggabungkan desain sampel berbasis kluster dengan error yang mungkin berkorelasi antar kluster
- Data observasi berulang sering korelasi residual dalam unit-unitnya
- Data runtun waktu sering memiliki error yang secara serial berkorelasi yaitu korelasi antar waktu
Strategi konvensional berbasis regresi untuk mengatasi korelasi residual
- Cluster-consistent covariance matrix estimator untuk menyesuaikan standard error
- Generalized Least Squares sebagai ganti OLS untuk mengidentifikasi struktur korelasi
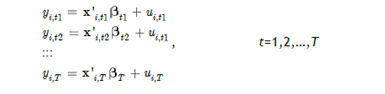
Anggap data terletak di setiap unit cross sections pada periode waktu T:
Atau dalam vektor :
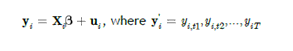
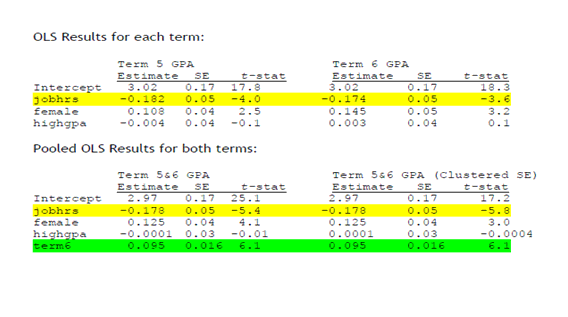
Untuk perbandingan, dimulai dengan dua model regresi linier OLS konvensional, masing-masing untuk setiap periode. Catat bahwa variable female highgpa (HS GPA) invarian dalam waktu (time-invariant).
Hasil OLS setiap semester
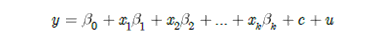
Model Data Panel dengan Efek Linier Unobserved
Motivasi: Heterogenitas Unobserved
Anggap kita mempunyai model dengan variabel unobserved time-constant, c:
Dimana u tidak berkorelasi dengan semua variabel penjelas di x.
Karena c tidak terobservasi maka c terserap ke error, jadi dapat ditulis
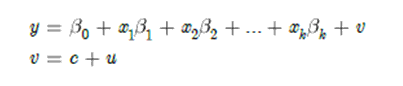
Estimasi OLS dari Model Komponen Error
Jika unobserved heterogenity ci berkorelasi dengan satu atau lebih variabel penjelas, estimasi OLS bias dan tidak konsisten.
Jika unobserved heterogenity ci tidak berkorelasi dengan variabel penjelas di x, OLS tidak bias bahkan dalam satu runtun cross sections
Jika kita memiliki lebih dari satu observasi di unit-unit, error akan berkorelasi dan estimasi OLS tidak efisien
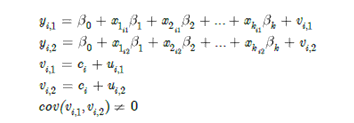
Unobserved Heterogenity pada Data Panel
Anggap data ada pada setiap unit cross section atas periode waktu T. Ini adalah unobserved effect model (UEM), disebut juga model komponen error. Kita bisa tuliskan model untuk setiap periode waktu:
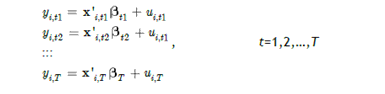
Dimana ada T observasi pada outcome y per individu i,
Xit adalah vektor dari variabel penjelas diukur pada waktu t
Ci adalah unobserved heterogenity dalam semua periode tetapi konstan dalam waktu
Uit adalah error istimewa yang time-varying
Estimasi yang konsisten dari Model Komponen Error dengan Pooled OLS
Jika kita asumsikan tidak ada korelasi kontemporer dari error dan variabel penjelas, estimasi Pooled OLS konsisten:
![]()
Estimasi yang efisien dari Model Komponen Error dengan Pooled OLS
Walaupun estimasi konsisten, pooled OLS bisa jadi tidak efisien.
Salah satu cara dengan mengkombinasikan pooled OLS dengan cluster-consistent standard error
Metode Panel GLS dipertimbangkan sebagai pilihan
Sumber:
Professor Patricia A. McManus. Introduction to Regression Models for Panel Data Analysis :Indiana University.
Workshop in Methods. October 7, 2011
